Based on a survey of 160 supply chain leaders in a recent Webinar conducted by Steelwedge Software, companies captured a whopping 70 percent more data (product, supply, demand and finance) to manage their organizations this year. Yet, 77 percent of these businesses are not actually leveraging this data in their S&OP processes, thereby leaving “blind spots” in their decision-making processes around critical supply/demand tradeoffs.
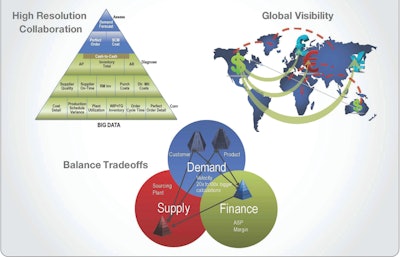
The term “Big Data” is not just an IT buzzword that supply chain folks can choose to ignore. It is becoming more and more of a reality—and valuable leveraging point—in their own organizations. As such, it is important to understand the three attributes to Big Data: volume, velocity and variability.
An example of volume in retail is the number of SKU-ship to combinations, which can run into millions then translate to billions of planning relations (SKU-ship to-customer). An example of variability is the demand pattern shifts that happen across a set of low-volume but high-value products which becomes difficult to forecast. This is common in industrial equipment and high-technology industries. An example of velocity is the rapid addition of new products in organizations and the need to plan for those products from a demand as well as supply perspective. These three factors combined have become critical for organizations to manage as part of their S&OP process.
When companies have a basic S&OP process, it is easier for them to create the plans at a monthly level and at an aggregate level of granularity such as product families or categories (Level 1 “reacting” on the Gartner Maturity model). However, when companies mature to higher levels such as Level 2 “balancing” or 3 “collaborating” or 4 “orchestrating,” then it is critical for them to be able to plan at a monthly level and also re-plan at ad-hoc frequencies to plan at a much more granular level (SKU, ship-to or customer level). Without the nuances of big data volume, velocity and variability, they can’t reliably power ad-hoc decision making required by today’s volatile business environments.
To meet the potential requirements for Big Data-enabled S&OP processes, include the ability to:
- Carry out volumetric and financial planning in the same environment
- Initiate global, corporate-wide S&OP planning and reporting
- Plan across operational and strategic time horizons in single environment
- Create global supply-demand scenarios
- Ensure real-time integration to back end systems
The key benefits that companies get as a result of the Big Data-enabled S&OP process are:
- A single, unified data model for supply, demand and finance
- The ability to do global scenario management across supply, demand and finance
- Extremely rich collaborative capabilities
Best yet is the business value of Big Data in S&OP. Big Data-enabled S&OP allows companies to do high resolution planning and analytics. With inherently greater accuracy and visibility, the following metrics will also get a big boost from Big Data: forecast accuracy; order to deliver lead-times; inventory levels; and cash-to-cash cycle times.
In 2013, expect to see Big Data become more of an issue in supply chain management (SCM). Expect to see a convergence of planning and analytics applications which must support Big Data. Also, supply chain professionals need to become more technology savvy on Big Data-related issues to be more responsive to the business requirements such as analyzing Point of Sale (POS) data; rapidly simulating the addition of new products; and the impact on the overall S&OP plan.



















